Introduction
This tutorial will show you how to formulate queries in SQL, which is short for Structured Query Language. It is a standard programming language that enables you to perform all sort of functions in a database, such as retrieving information, entering data, manipulating data, and creating tables. This tutorial will only discuss SQL as a querying language. This means that you use SQL to formulate queries, being structured requests for information. If these queries are sent to a database, it will respond by sending back the requested information, normally in the form of a table.
The SQL keywords that will be discussed in the following sections are SELECT, FROM, WHERE, GROUP BY, HAVING and ORDER BY. The general syntax of an SQL is as follows:
SELECT [DISTINCT] <names of columns>
FROM <names of tables>
[WHERE <condition> ]
[GROUP BY <names of columns> ]
[HAVING <condition> ]
[ORDER BY <names of columns> [ASC | DESC] ]
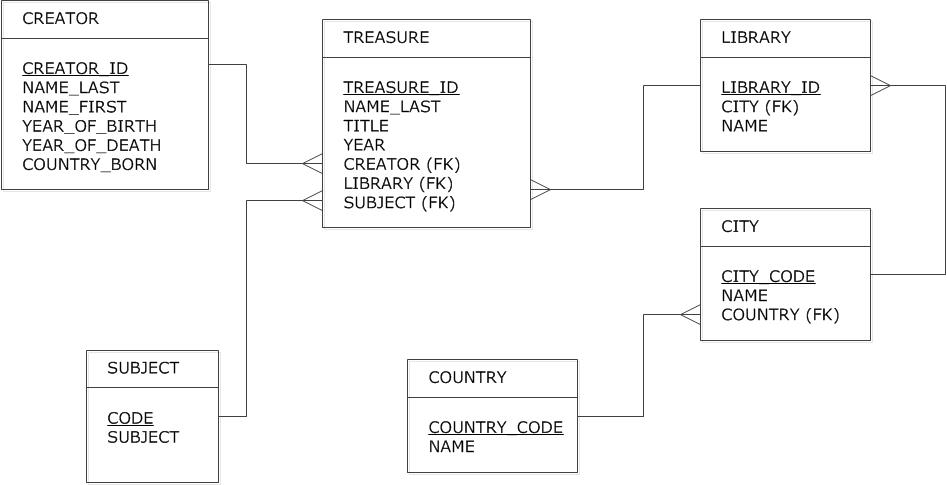
To illustrate the points that are made, this tutorial will make use of a sample database that stores information on treasures from various European libraries. The information has been taken from www.theeuropeanlibrary.org. The database firstly contains a table with the name TREASURE, which contains the following attributes: title, year, creator, library and subject. The primary key in this table has the name treasure_id. This table contains three foreign keys. Firstly, the attribute creator refers to the table CREATOR which has the following attributes: creator_id , the primary key, name_last, name_first, year_of_birth, year_of_death, and country_born. Secondly, the attribute library in TREASURE refers to the table LIBRARY and provides data on the library where the treasure is kept. The table LIBRARY stores information on the name and the city of the library. The primary key is library_id. A third foreign key in the table TREASURE is SUBJECT, which is a reference to the table SUBJECT. A subject_code has been used as a primary key, and a description of this code is also provided, as subject. Separate tables have been made for the names of countries and cities. These tables serve to normalise the spelling of geographical names. The table LIBRARY contains a code representing the city in which this library is located. The full name of this city can be retrieved from the table CITY.
Another description of this database is given below, in the form of an entity-relationship diagram.