2. Framework
XSLT can be used to transform XML files into other XML files. An XML file is essentially a collection of data which have been structured according to a certain logic. XSLT can be used to re-structure these data. We can change the elements that are used to encode the text. We can also sort certain data values alphabetically of numerically. It is also possible to add certain data to the document or to filter the contents of the document, on the basis of a given criterion. XSLT is used most frequently to transform the XML file into an (X)HTML file. The aim, in many cases, is to covert the XML-encoded text into a web page that can easily be understood by human readers.
The data in an XML file are always structured hierarchically. A well-formed XML file can always be represented as a tree diagram. The result of the transformation will also be a document that is structured hierarchically. It is often said that XSLT transforms a source tree into a result tree.
The program that performs the transformation is called an XSLT processor. Such a program reads both the XML source file and the XSLT script and produces a result on the basis of these two. A great number of XSLT Processors can be downloaded free of charge. Examples include XALAN and SAXON. The XML editor Oxygen includes a numer of buit-in XSLT processors. Appendix A contains instructions on how such XSLT processors can be used.
To explain how XSLT works, this tutorial shall make use of a relatively simple XML document as a source document. The name of this documents is collection.xml. It is a brief document that describes three letters from the collection of Leiden University Library. The actual bibliographic information has been simplified slighty for pedagogical purposes. This source XML document is provided below.
In the previous section, it was explained that XSLT can transform a source tree into a result tree. As XSLT can be a rather difficult technique to learn, we shall make use of a relatively simple XML file in this tutorial. The folder that you need to dowload for this course (< 3 kB) contains a file with the name collection.xml. This XML file describes a small part of the letter collection of Leiden University Library. The DTD on which this XML file is based is also included in this folder. The name of the DTD is collection.dtd. The structure of the XML-file can be represented as follows:
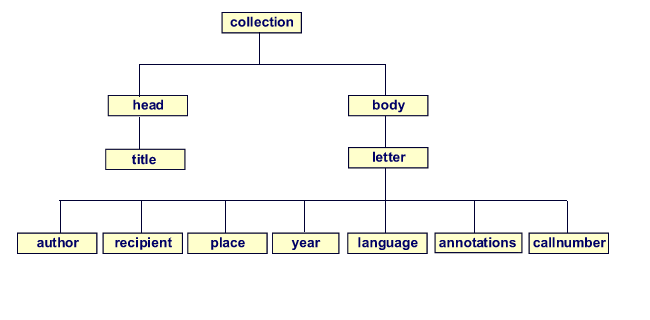
Before you start working with XSLT, it is important to make sure that a number of central terms are clear: (1) the document element (2) the root node and (3) direct children.
- The document element, which is also referred to as the root, is the element that contains all the other elements. In a tree diagram representing the XML document, the document element is always shown at the very top. In the XML file that is used in this course, the document element has the name collection. This document element contains all the other element. It is not contained within another element itself.
- In an XML-file, the document element (or the root) is normally preceded by a number of
other lines. There is usually an XML declaration, and sometimes the document
may also include certain processing instructions, such as a reference to a
stylesheet. The information preceding the root of the XML tree may, under
certain circumstances, also be relevant. The term root node is used
to refer to the absolute beginning of the file. This root node starts at the very first
character of the document. The difference between the root and the root node is also clarified in the illustration below.

- The term direct children refers to the immediate subelements of a certain element. From the tree diagram above, it can be seen that <body> is a direct child of <collection>, whereas <author> is NOT.